

View on GitHub
Open this notebook in GitHub to run it yourself
Classical Neural Networks
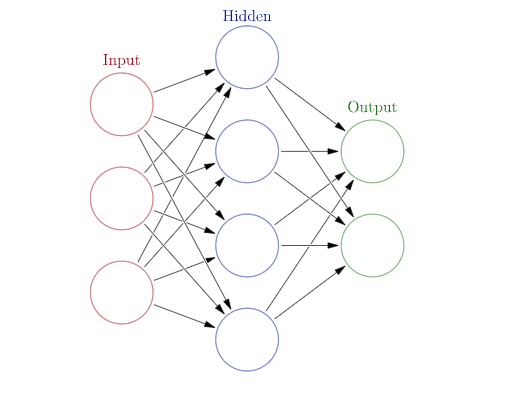
Neural networks is one of the major branches in machine learning, with wide use in applications and research. A neural network—or, more generally, a deep neural network—is a parametric function of a specific structure (inspired by neural networks in biology), which is trained to capture specific functionality. In its most basic form, a neural network for learning a function looks as follows:- There is an input vector of size (red circles in Fig. 1).
- Each entry of the input goes into a hidden layer of size , where each neuron (blue circles in Fig. 1) is defined with an “activation function” for , and are parameters.
- The output of the hidden layer is sent to the output layer (green circles in Fig. 1) for , and are parameters.
Quantum Neural Networks
The idea of a quantum neural network refers to combining parametric circuits as a replacement for all or some of the classical layers in classical neural networks. The basic object in QNN is thus a quantum layer, which has a classical input and returns a classical output. The output is obtained by running a quantum program. A quantum layer is thus composed of three parts:- A quantum part that encodes the input: This is a parametric quantum function for representing the entries of a single data point.
- A quantum ansatz part: This is a parametric quantum function, whose parameters are trained as the weights in classical layers.
- A postprocess classical part, for returning an output classical vector.
Example: Hybrid Neural Network for the Subset Majority Function
For an integer and a given subset of indices we define the subset majority function, that acts on binary strings of size as follows: it returns 1 if the number of ones within the substring according to is larger than , and 0 otherwise, For example, we consider and :- The string 0101110 corresponds to the substring 011, for which the number of ones is 2(>1). Therefore, .
- The string 0011111 corresponds to the substring 001, for which the number of ones is 1(=1). Therefore, .
Generating Data for a Specific Example
Let us consider a specific example for our demonstration. We choose and generate all possible data of bit strings. We also take a specific subset .Constructing a Hybrid Network
We build the following hybrid neural network: Data flattening A classical linear layer of size 10 to 4 withTanh activation A qlayer of size 4 to 2 a classical linear layer of size 2 to 1 with ReLU activation.
The classical layers can be defined with PyTorch built-in functions.
The quantum layer is constructed with
(1) a dense angle-encoding function
(2) a simple ansatz with RY and RZZ rotations
(3) a postprocess that is based on a measurement per qubit
The Quantum Layer
Output:
The Full Hybrid Network
Now, we can define the full network.Training and Verifying the Networks
We define some hyperparameters such as loss function and optimization method, and a training function:train function:
check_accuracy, which tests a trained network on new data:
Training and Verifying the Network
For convenience, we load a pre-trained model and set the epoch size to- Training a network takes around 30 epochs.
Output:
Output: